class: center, middle, inverse # Two Sigma RentHop Competition Matthew Emery [(@lstmemery)](https://github.com/lstmemery) June 1st, 2017 --- # Winning Kaggle Competitions by KazAnova 1. Understand the Data 2. Understand the Metric 3. Cross-Validate Early! 4. Hyperparameter Tuning .footnote[[Source](https://www.hackerearth.com/practice/machine-learning/advanced-techniques/winning-tips-machine-learning-competitions-kazanova-current-kaggle-3/tutorial/)] --- # Who are Two Sigma and RentHop? - Two Sigma: AI Heavy New York Hedge Fund - RentHop: Smart Apartment Search (New York Only) - Reward: Recruitment to Two Sigma 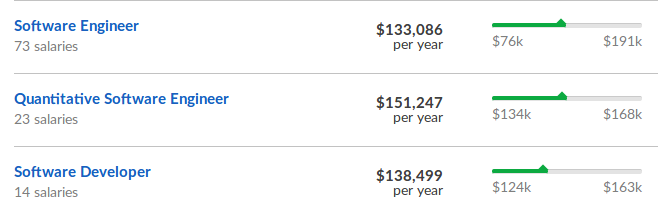 .footnote[[Source](https://www.glassdoor.com/Salary/Two-Sigma-Salaries-E241045.htm)] --- # The Goal - Predict how interested people will be in this: 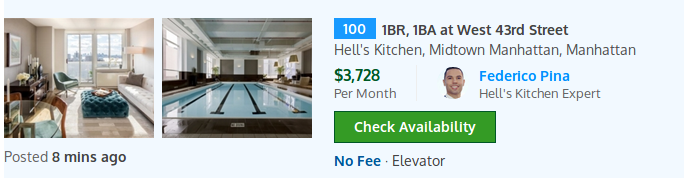 --- # Understanding the Data Training: 49352 Rows Test: 74659 Rows - Location Data - Natural Language Data - Image Data (78.5 Gb compressed) - ...and everything you would else you would expect (price, bedrooms etc.)  --- # Understand the Metric Multiclass Log Loss (Low, Medium, High Interest) <img src ="../images/logloss.png" height="80%" width="80%" alt = "Log Loss"> - Note: This isn't ordinal --- ## Manager ID Count <img src ="../images/manager-sales-count-plot.jpeg" height="419" width="596" alt = "Manager Count Plot"> Someone just used different transformations of Manager ID Count and scored in the top 15% .footnote[[Source](https://blog.nycdatascience.com/student-works/renthop-kaggle-competition-team-null/)] --- ## Listing ID <img style="float: left; margin-right: 5%;" src ="../images/listing_id.png" height="70%" width="50%" alt = "Listing ID"> - This pattern hinted at a possible data leak... .footnote[[Source](https://www.kaggle.com/zeroblue/visualizing-listing-id-vs-interest-level)] --- ## Data Leak The creation time of the image folders were correlated with interest. <img style="float: left; margin-right: 5%;" src ="../images/leak.png" height="50%" width="50%" alt = "Leak Plot"> - X-Axis: Day - Y-Axis: Seconds - .blue[Blue=Low] - .green[Green=Medium] - .red[Red=High] .footnote[[Explanation](https://www.kaggle.com/c/two-sigma-connect-rental-listing-inquiries/discussion/32404)] --- ## Feature Engineering A few interesting ones: - Grouping by categorical features and finding count/median/mean/standard deviation of numerical ones. (3rd Place) - Inferring Points of Interest from text descriptions (Supermarket, Subway, etc.) (2nd Place) - Leveraging duplicate data (Leads and lags on pricing) (11th Place) - Exclamation marks in description - Reverse GeoCoding New York Neighbourhoods --- ## Second Place Solution @Faron ``` - 32 LightGBM models - 9 Extreme Tree models (sklearn) - 7 RF models (sklearn) - 5 Keras models - 3 XGBoost models - @KazAnova's StackNet example base-level predictions ``` Best Model: LightGBM (CV: 0.50135/ Test: 0.50557) Meta-modeled with a 2-layer neural network. --- ## An Aside on LightGBM  - Faster than XGBoost - Requires more hyperparameter optimization --- ## Second Place Solution Grid-Search Bagging Grid Search: Check cross-validation scores for each hyperparameter in regular intervals. e.g. Check maximum depth of XGBoost from 1 to 10. Bagging (Bootstrap AGGregating): Sample the data many times, with replacement For each of 12 bags: Grid search hyperparameters If the new hyperparameters is better, blend it into the model --- ## StackNet Written by Marios Michailidis (kazAnova) for his PhD A Java-based, flexible meta-modelling network 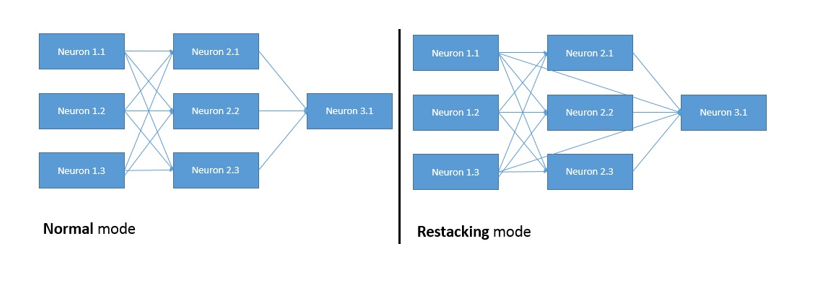 [Source](https://github.com/kaz-Anova/StackNet) --- #References [2nd Place Solution](https://www.kaggle.com/c/two-sigma-connect-rental-listing-inquiries/discussion/32148)