Galaxy Zoo Competition
Matthew Emery
https://lstmemery.github.io/kaggle-galaxy-presentation/#/
- All sky galaxy surveys produce more images than can be handled just by experts
- It’s 2011, better crowd-source it
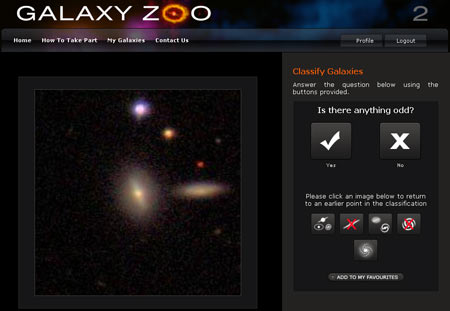
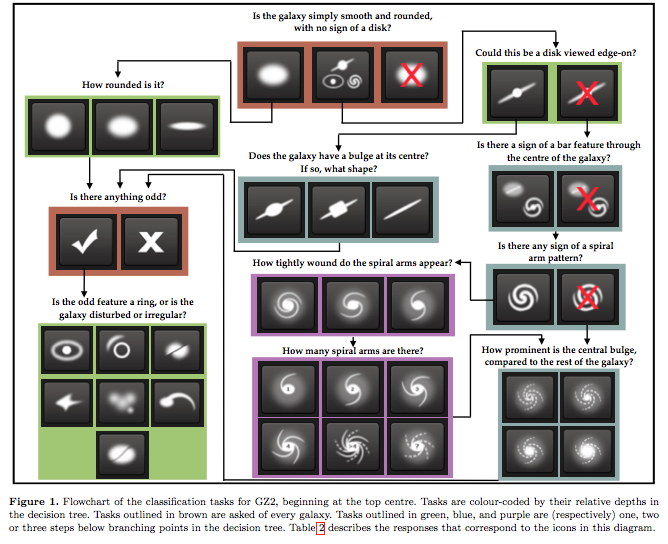
Specifications
- Ran from December 20th, 2013 to April 4th, 2014
- 61,578 training images with vote fractions
- 79,975 test images
- 424 x 424 pixels
- Prize of $16,000

Loss Function
- This is a regression problem!
- The answers to the first question should sum to 1
- Answers to the next questions to sum to their parent probability
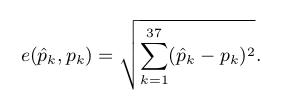
- Note: We are measuring error against the what the crowd answered. A “good” model will have the same biases as the crowd
- Avoided cropping out the object interest by centering with SExtractor (Source Extractor)

Data Augmentation

- Rotating uniformly from 0 to 360
- Translating uniformly -4 pixels to 4 pixels
- Scaling log-uniformly from 1.3^-1 to 1.3
- Flip as a Bernoulli event with probability 0.5
- Color perturbation using an equation in the ImageNet paper
- This is all being done on the CPU while the GPU trains the network
Rotational Invariance
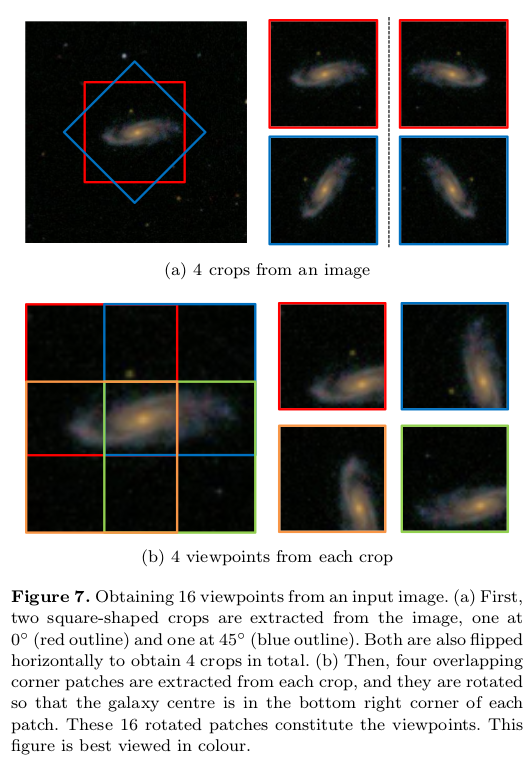 Step 1: Rotate image 45 degrees and flip both images (4 images)
Step 1: Rotate image 45 degrees and flip both images (4 images)
Step 2: Crop each 67x67 image into 4 overlapping 45x45 images (4x4=16 images)
Best Model
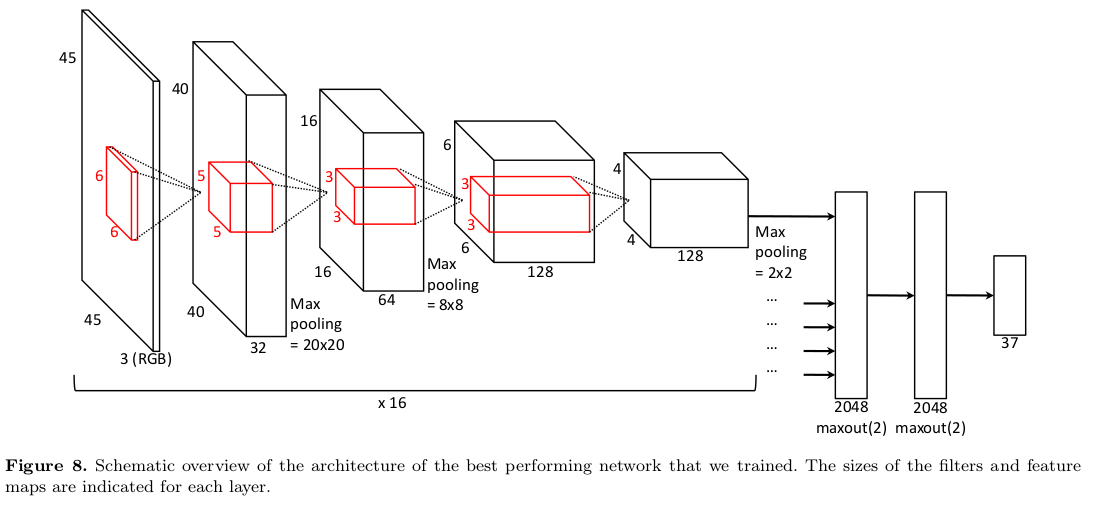
- All 16 viewpoints are fed in at the same time to maximize parameter sharing
- Best single model has 4 square convolutional layers (6-5-3-3)
- More than 100 models were tested, 17 were included in the final ensemble
- Maxout are like group-wise ReLUs
- The 37 were scaled to their constraints
Training
- 67(?) hours of training for the best model on a GTX 680
- Nesterov Momentum was used (16 “minibatches,” effectively 256 because of architecture)
- Learning rate of 0.04 (updated to 0.004 after 18M samples, then 0.0004 after 23M)
- Dropout was used during training to prevent overfitting
How Did He Do?
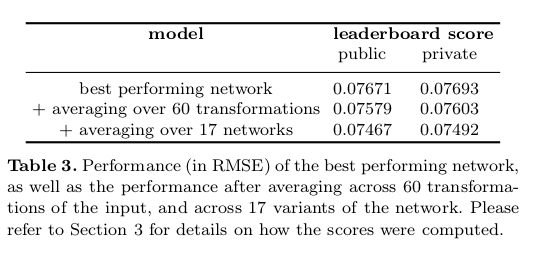
- His single best network outperformed everything else